PMN at Glencairn Elementary School Science Night
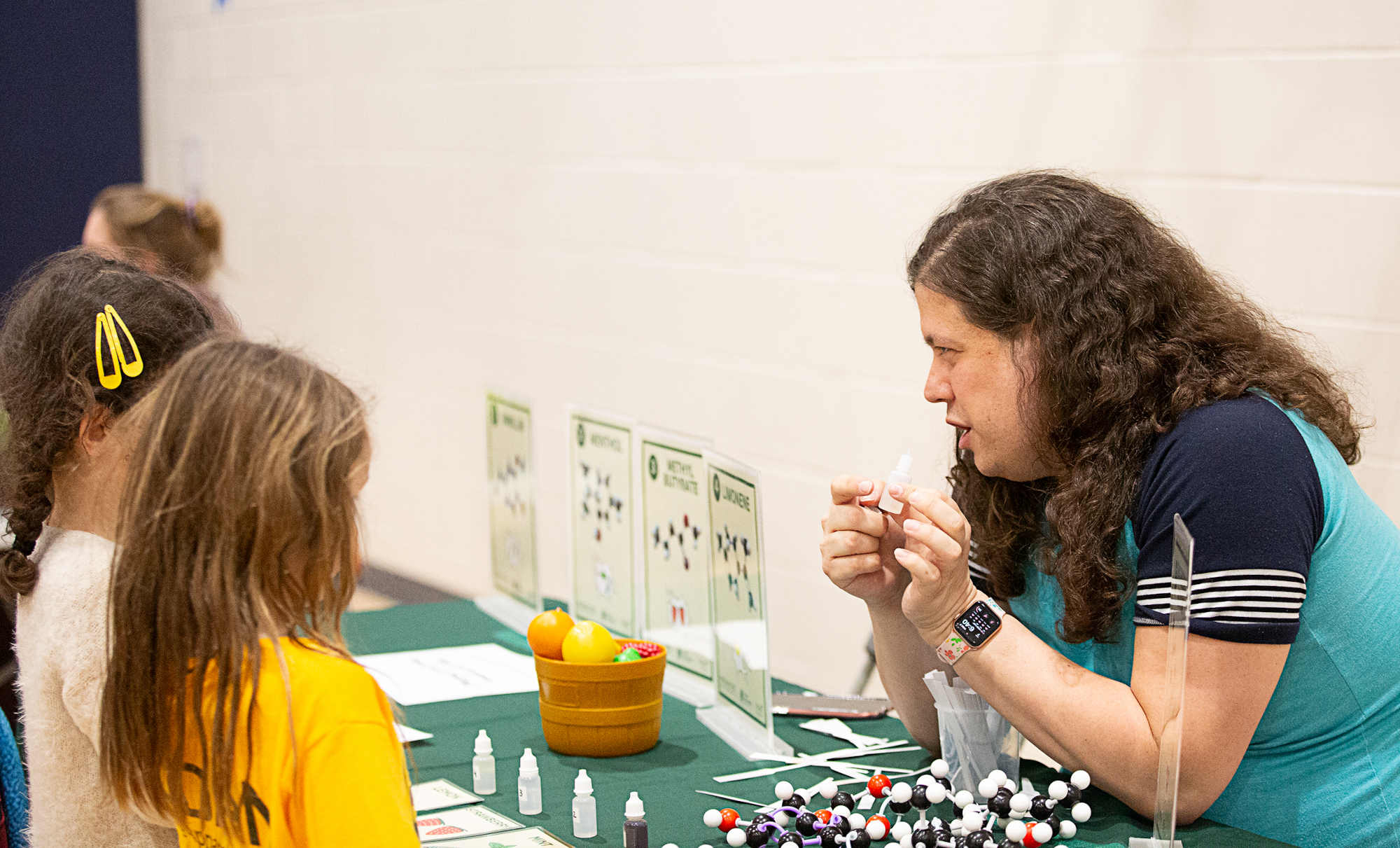
February 7, 2024 was Science Night at the local Glencairn Elementary School here in East Lansing, MI, and PMN was there with a booth, run by PMN director Dr. Charles Hawkins! We called our booth “Why do bananas smell so a-peeling”, and we showed students and their families all about how the wonderful smells of fruits and other plants are actually caused by chemistry and metabolism. Students learned about how the different molecules produced by plants give each of them their distinct smell, and played a guessing game where they matched scents to their plants of origin. They also got to see and touch models of the molecules that produce each smell, and searched through them to identify their favorite!
The kids had a great time, and somewhere around 50 visited the booth. It was great fun for all involved, and we definitely plan to be back next year! Also, if you’re in the greater Lansing area, PMN will also be at MSU SciFest April 13 and 14 at [insert location info], so come by and see us!

